
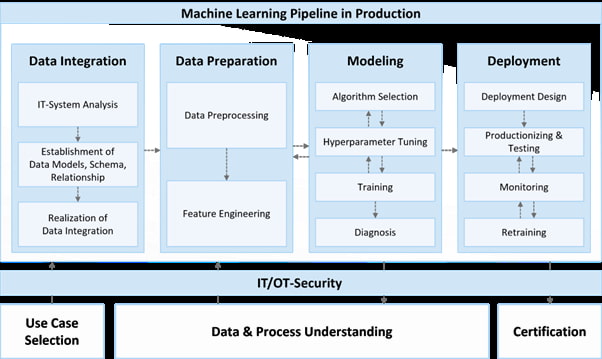
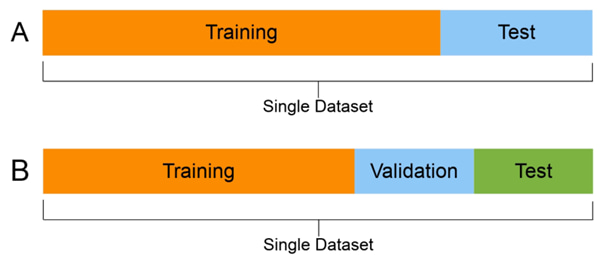
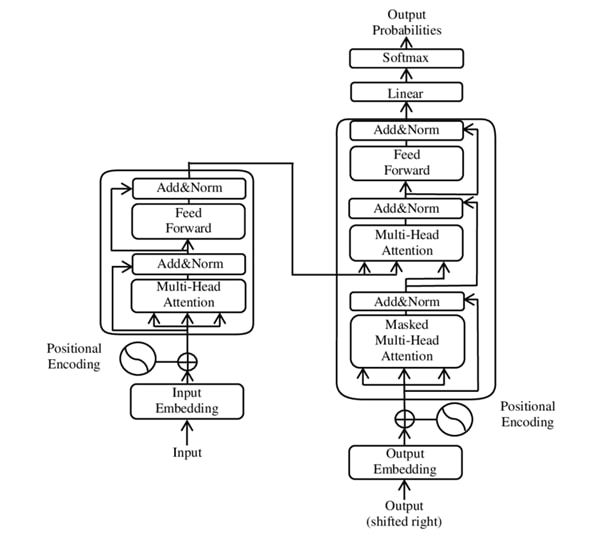
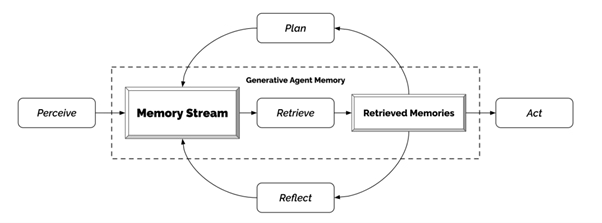

How Gen Z is Embracing AI for Flirting, Emotional Support, and Connection
Feb 02, 2026
Research
In a world where technology increasingly defines our interactions, using AI for flirting is no longer a futuristic concept —...
